确认服务器信息和其他
本人使用的是云服务器相关配置如下:
| 服务器信息 | 时间 | 配置 | 带宽 | 硬盘 | 价格 |
|---|---|---|---|---|---|
| 腾讯轻量应用服务器(上海)(CentOS) | 一年 | 2核4G | 5M | 60G | 218 |
| 阿里轻量应用服务器(上海)(CentOS) | 一年 | 2核4G | 3M | 50G | 108 |
| 华为弹性云服务器(上海)(CentOS) | 一月 | 2核2G | 3M | 40G | 95 |
这三台机器都是趁着打折比较便宜的时候入手的,因为一个账号只能购买一台,如果有条件的话还是建议尽量选择一个厂商的一个地区,这样可以减少网络损耗时间,也可以减少网络配置中遇到一些问题。
安装过程
基础环境配置
1、关闭SELinux
vim /etc/selinux/config
修改
SELINUX=disabled
2、关闭防火墙
由于服务器之间需要相互网络请求,所以设置相互之间所有端口开放,在腾讯云和华为云里面可以修改安全组里的配置,由于阿里云不是EC2没有安全组,只能手动去配置开放一些端口,这部分我相信不用教学,放几张图大家自己配置即可。
- 腾讯云
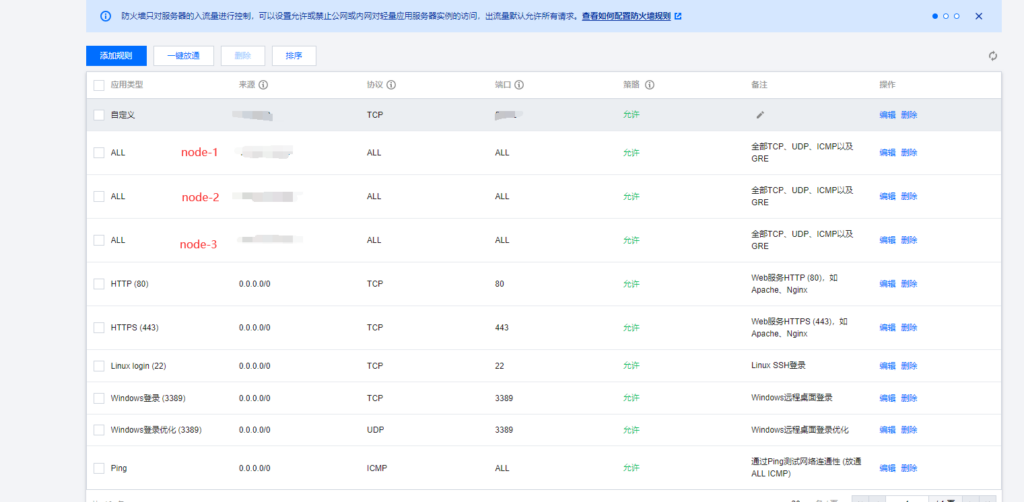
- 阿里云
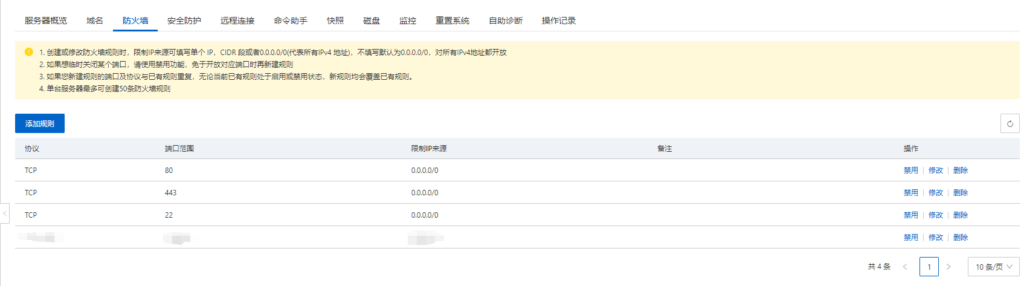
- 华为云

3、配置hosts
这一步至关重要!
我在搭建的时候就坑在这个地方,这里十分关键
首先来设置hostname,如果你拿到新主机一定要设置hostname和hosts文件
vim /etc/hostname我使用的是node-1、node-2、node-3,你们可以根据自己喜欢的方式命名
然后就是关键的修改hosts文件了
vim /etc/hostsnode-1
node-1的内网ip node-1
node-2的外网ip node-2
node-3的外网ip node-3node-2
node-1的外网ip node-1
node-2的内网ip node-2
node-3的外网ip node-3node-3
node-1的外网ip node-1
node-2的外网ip node-2
node-3的内网ip node-3再强调一遍,这一步很关键,影响到后期从节点是否能正常把心跳发送个NameNode和ResourceManager以及是否能正常启动NameNode和ResourceManager
设置完之后ping一下自己,看看是否会出现ping 127.0.0.1
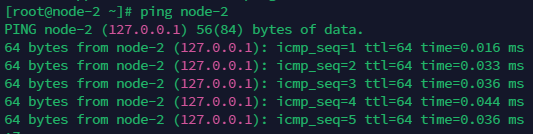
这样是有问题的,这会导致后期NameNode和ResourceManager的监听地址变成了127.0.0.1:9000和127.0.0.1:8031这显然是不对的

正确的应该是ping自己返回自己的内网ip,监听端口同理

这里使用内外网的ip主要可以参考下图,详细细节大家想要深入的话可以自行搜索了解,这里不做过多解释
4、安装ssh
ssh-keygen
连着回车三次就会看到/root/.ssh/生成了公钥和秘钥文件
然后我们在三台机器,同时将公钥拷贝到node-1
ssh-copy-id node-1接着我们就会看到
接下来,我们只需要把放有所有服务器公钥的authorized_keys分发到每一个节点就可以了
cd /root/.ssh/
scp authorized_keys node-2:$PWD
scp authorized_keys node-3:$PWD
接下来在node-2上尝试
ssh node-3如果不用输密码就可以直接登录进去,那么就证明没问题了
安装JDK和Hadoop
1、安装jdk
首先看看环境有没有预装jdk,如果有则卸载
rpm -qa | grep jdk
如果没有,直接开始安装,如果有
rpm -e --nodeps java*创建目录存放软件包
mkdir /opt/module
mkdir /opt/software我安装的是官网下载的jdk1.8,将包发送到/opt/module/目录下之后
# 解压jdk1.8
tar -zxvf jdk-8u144-linux-x64.tar.gz -C ../module/
mv /opt/module/jdk1.8.0_144 /opt/module/jdk-1.8
# 配置环境变量
vim /etc/profile
# java-1.8
export JAVA_HOME=/opt/module/jdk-1.8
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
java -version
然后分发到每一台机器上
cd /opt/module
scp -r jdk-1.8 node-2:$PWD
scp -r jdk-1.8 node-3:$PWD
cd /etc
scp profile node-2:$PWD
scp profile node-3:$PWD
#在node-2和node-3上
source /etc/profile
java -version2、安装Hadoop
我安装的是官网下载的Hadoop-2.7.2,还是将包发送到/opt/module/目录下
# 解压hadoop-2.7.2
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/vim hadoop-env.sh
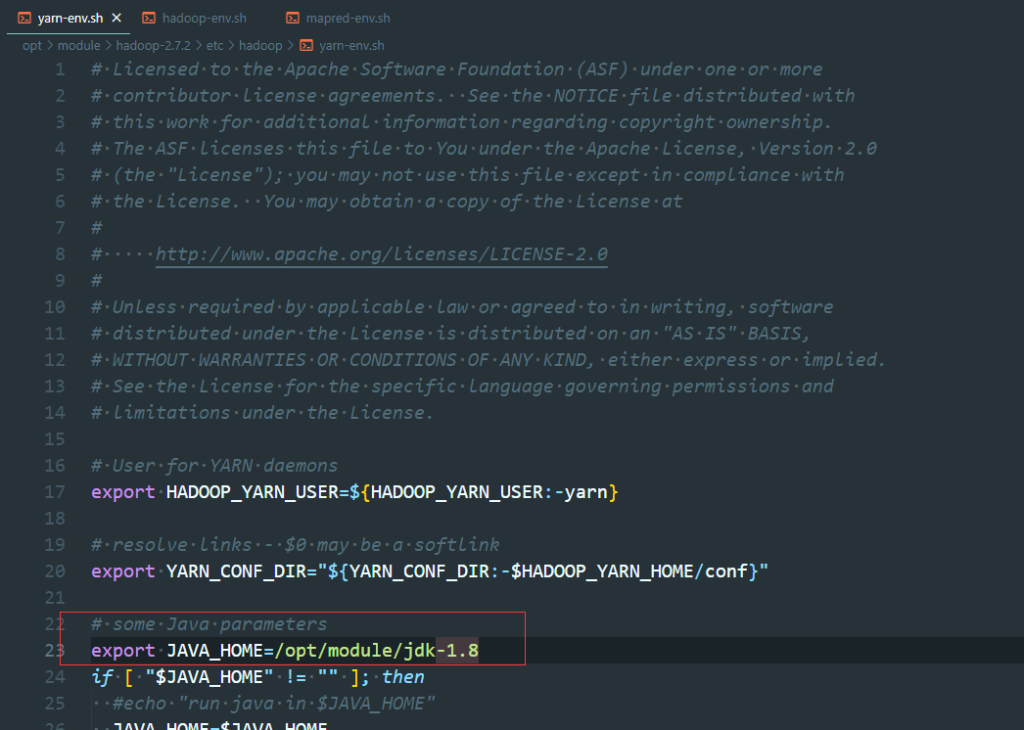
vim yarn-env.sh
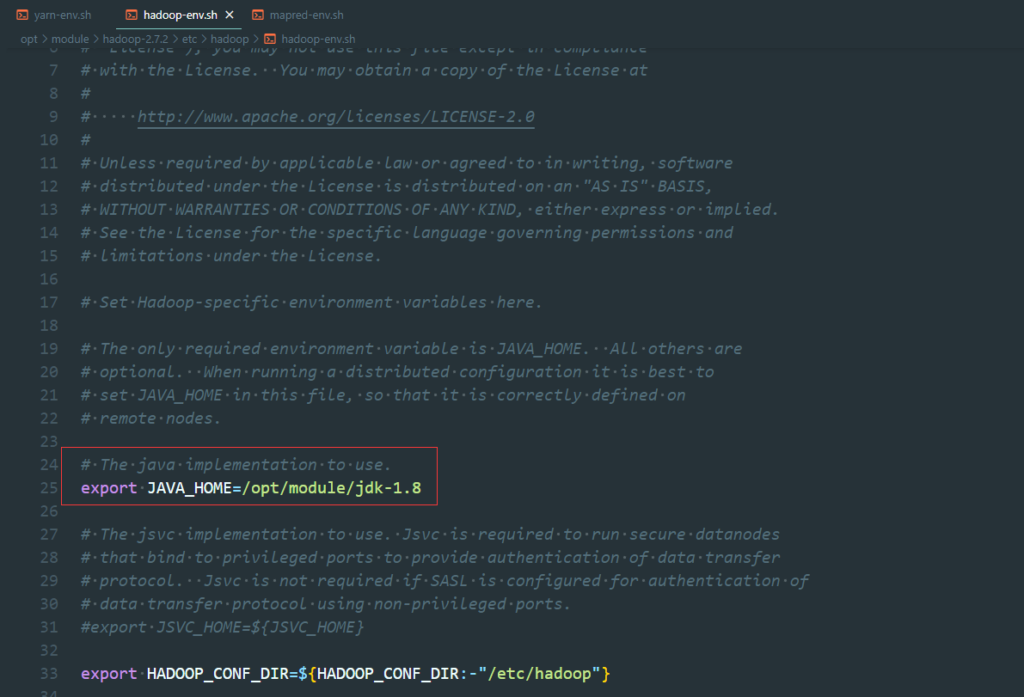
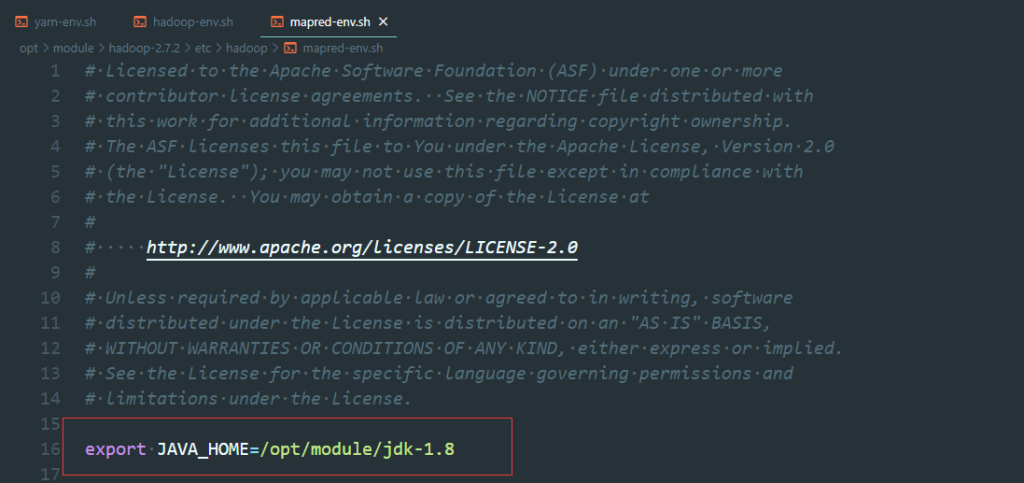
vim mapred-env.sh
vim core-site.xml
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node-1:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
vim hdfs-site.xml
<configuration>
<!--副本数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondarynamenode的地址,辅助namenode工作 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node-2:50090</value>
</property>
</configuration>
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration>
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node-2</value>
</property>
</configuration>
vim slaves
node-1
node-2
node-3
配置hadoop的环境变量
vim /etc/profile
# hadoop-2.7.2
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
同样的,在node-1上配置好之后,分发到其他的服务器上
cd /opt/module
scp -r hadoop-2.7.2 node-2:$PWD
scp -r hadoop-2.7.2 node-2:$PWD
cd /etc
scp profile node-2:$PWD
scp profile node-3:$PWD
#在node-2和node-3上
source /etc/profile格式化集群
hadoop namenode -format
注意:在node-2上进行:start-all.sh注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 yarn,应该在
ResouceManager所在的机器上启动yarn。
然后用jps查看一下进程状态
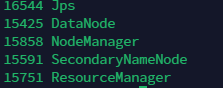
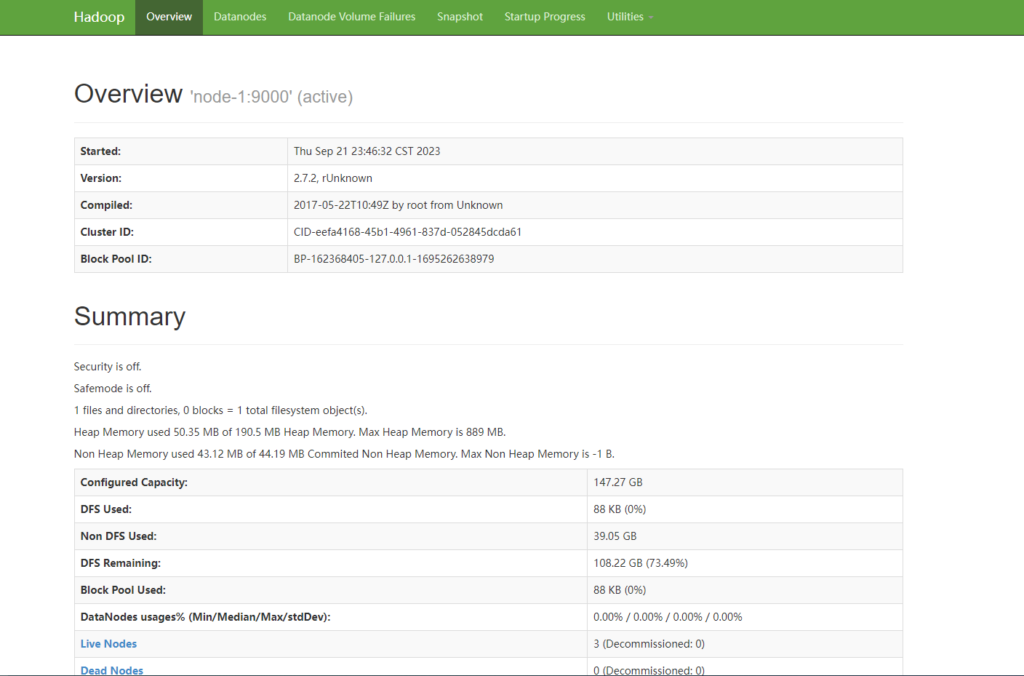
然后访问一下页面:
NameNode ip:50070
SecondaryNameNode ip:50090
ResourceManger ip:8088
如果正常启动,节点显示也正常,那么恭喜你,可以开始体验hadoop了